
Na současných webech můžete najít hned několik typů obsahu – texty, obrázky a videa, ale také stále využívanější komplexní aplikace a interaktivní funkce, které vám denně běží v prohlížeči. A právě ty fungují pomocí JavaScriptu. Jak to vnímají vyhledávače? Kdy byste se měli o JavaScript SEO vůbec zajímat?
JavaScript – asi každý o něm někdy slyšel. Jedná se o skriptovací jazyk, který slouží k tvorbě interaktivních webových stránek. Využívá se k vytváření jednoduchých animací, ale také složitých aplikací a akcí.
Opakování matka moudrosti
Nejprve si trochu připomeneme indexaci. A pak se podíváme na to, jak robot zpracovává JavaScript a kde můžete narazit na onen kámen úrazu.
Indexace
Indexace se dá zjednodušeně popsat jako ukládání jednotlivých URL adres do databáze během toho, jak robot web prochází. Soubor stránek, které jsou pro vás důležité a chcete na ně být vidět, se potom označuje jako index.
Měly by zde být pouze ty podstatné stránky. Snažte se proto čas, který robot crawlování webu věnuje, co nejlépe zúročit. Nebojte se využít i odebírání stránek z indexu.
Indexace a zpracování JavaScriptu vyhledávačem Google
Přichází otázka, která asi zajímá všechny nejvíc. Umí Google zpracovat a zaindexovat javascriptové weby? Ano! Nabízí se 3 způsoby, jak vyhledávači JavaScript naservírovat:
- Necháte to na vůli vyhledávače
- Server side rendering
- Dynamic rendering
Každý ze způsobů má své výhody i nevýhody. A protože je samotné téma renderování webů dost obsáhlé, rozebereme jednotlivé způsoby hodně okrajově.
1. Nechte to na vyhledávači
Tento způsob využijete v případě, že SEO „tolik neřešíte“. Nejste tedy obrovský e-shop se statisíci URL adres. Existují základy, které je ale důležité mít postavené dobře a správně.
Zpracování JavaScriptu
Když Googlebot narazí na JavaScript, začíná trochu jiný postup indexace, než tomu bylo u klasických jednoduchých stránek. Zpracování JavaScriptu zahrnuje 3 hlavní fáze:
- Crawling (procházení)
- Rendering (vykreslování), ze kterého získá další URL adresy
- Indexace
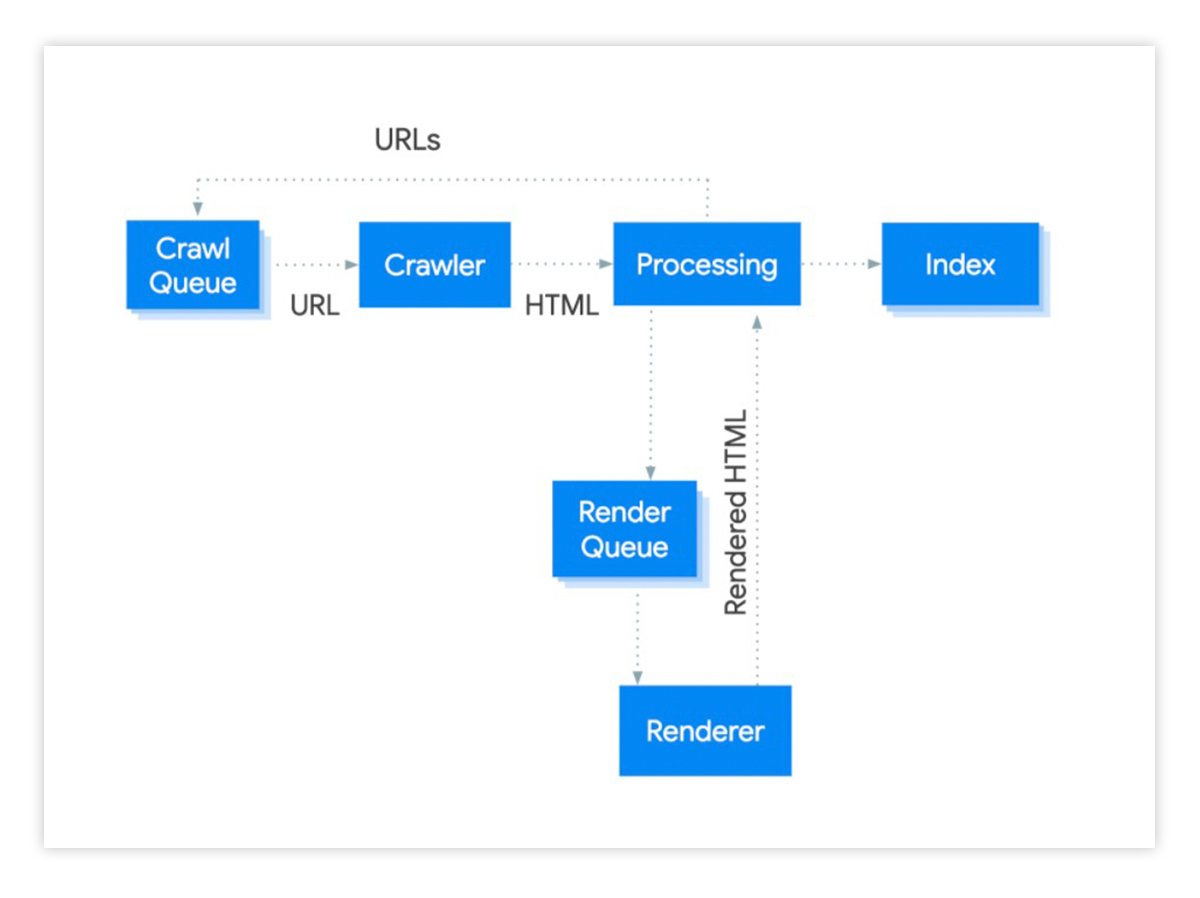
Nutno říct, že Googlebot nekliká ani nescrolluje. Přijde na odkaz, stáhne URL a zase odejde. Přichází bez cookies a s prázdnou local storage.
Jak můžete vidět z obrázku, při crawlovaní stránky s JavaScriptem se proces indexace trochu protahuje – robot musí nejdřív stránku stáhnout ze zdrojového kódu, vykreslit ji, získat odkazy na další URL a zařadit je do fronty (render queue). Projde je, vykreslí, získá další odkazy a tak pořád dokola. A až pak stránky indexuje.
U velkých webů může protahování způsobit potíže s crawl budgetem. Může tak dojít k tomu, že robot váš web opustí, protože už vyčerpal čas a neindexuje stránky, které jsou pro vás důležité. A to je jen první problém. Google nestíhá renderovat a indexovat velké weby, neumí některé javascriptové funkce spustit sám a renderování může trvat i týdny.
Mnohem přehlednější pro vás bude tabulka, která hezky popisuje, co Google dokáže zaindexovat a co ne.

2. Server side rendering
Server side rendering (SSR) funguje na principu izomorfního JavaScriptu. Izomorfní JavaScript nebo aplikace kombinuje výhody SPA (single page application) a MPA (multi-page application). Ve výsledku to znamená, že jste schopní spouštět stejný kód na serveru i ve vašem počítači.
Jak server side rendering probíhá?
- První požadavek dostane kompletní HTML (titulek, obsah, popisek – prostě vše textové), všichni dostanou to stejné.
- Lidem se po načtení HTML spustí JavaScript. Pomocí JavaScriptu se stránky „oživí“, cokoliv potom člověk na webu dělá, spouští se přes API požadavek na server a URL se mění pomocí AJAX + pushState.
- Vyhledávač dostal potřebné informace v HTML a je spokojený.
Pro naprostou většinu webů je SSR tou nejlepší volbou. Existují už zaběhnuté procesy, jak by vše mělo fungovat a jak by se to mělo chovat. Výhodou SSR je, že lidé i roboti získají obsah i bez JavaScriptu. Máte tedy téměř 100% jistotu, že se vše potřebné dostane k vyhledávačům. Nevýhodou je potřeba na serveru renderovat obsah pro obě strany – lidi i roboty. Pokud nepoužíváte cache, první request bývá dost pomalý. Takže používejte cache!
3. Dynamic rendering
Máte-li javascriptový web o milionech URL adres, případně velký zpravodajský web, pak je pro vás dynamic rendering trefa do černého. Tento typ renderování funguje na principu detekce vyhledávače a uživatele. Ve zkratce – každému poskytuje trochu něco jiného.
Jak Dynamic rendering probíhá?
- Zjistíte si na serveru, že pro stránku přišel robot (třeba pomocí user agenta).
- Podle toho se můžete zachovat různě k lidem a různě k robotům. Lidem můžete poslat JavaScript, aby se jim v prohlížeči vykreslila webovka správně a plnohodnotně.
- Robotům posílání odkloníte, pošlete jim jen statické HTML bez těch všech (Java)scriptů.
- Roboti budou spokojení a uživatelé taky.
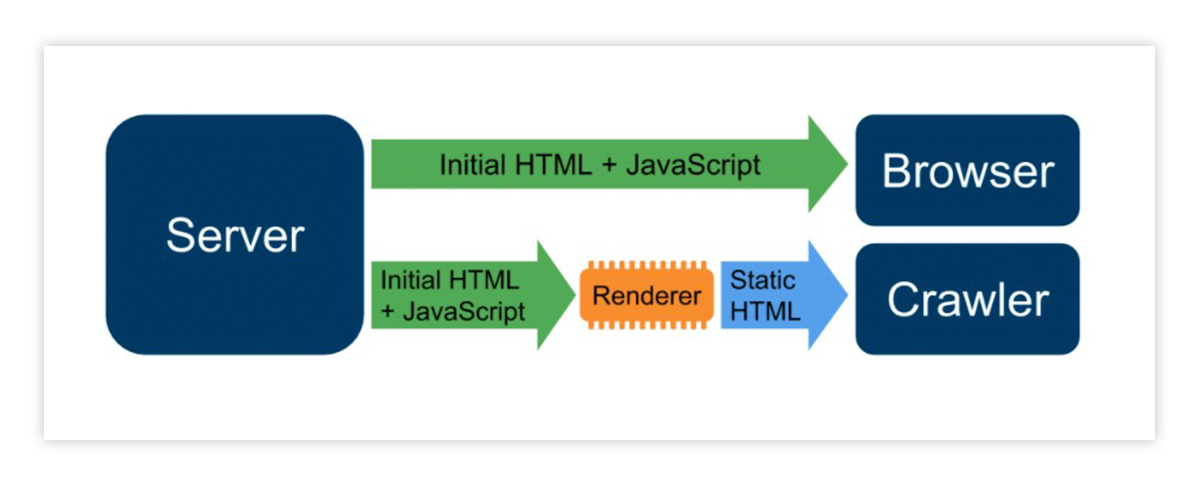
Jak renderovat?
- Puppeteer
- Rendertron
- Vlastní řešení s PhantomJS, JSDOM, Chrome Headless
- Prerender.io, PhantomJS as a service
Pozor na maskování
Dynamic rendering by se dal snadno zneužít k maskování (cloaking), jelikož můžete jiný obsah poskytnout uživateli a jiný vyhledávači. Pokud to bude jen v malé míře, Google to nebude považovat za maskování. Problém nastává ve chvíli, kdy lidem pošlete stránku s jablky a vyhledávačům s hruškami.
SSR a Dynamic rendering toho mají hodně společného
Tyto metody zvládají nejen vyhledávače Google, Seznam, Bing, ale i sociální sítě (Facebook, Instagram, Pinterest apod.). V tom mají oproti „ponechání“ na robotovi navrch.
7 pravidel indexace javascriptových webů podle Jaroslava Hlavinky
Google umí zhruba od roku 2015 zpracovat JavaScript. To ale neznamená, že je to standard. U propracovanějších javascriptových webů stále platí, že potřebují lásku a péči. Na nedávném školení o technickém SEO od Jaroslava Hlavinky a Pavla Ungra jste se mohli dozvědět o 7 pravidlech, které je dobré dodržovat, pokud toužíte po hladkém zaindexování stránek vašeho webu.
1. Každý důležitý stav aplikace má vlastní URL
Kdykoliv bude uživatel procházet webem, je potřeba aby se měnila URL adresa. Jedná se o:
- Výpisy
- Detaily (produktu)
- Stránkování
- Filtrace
- A v některých případech i hledání (tady ale prosím s rozmyslem, vše se dá omezit pomocí robots.txt)
Představte si to například při vybírání parametrů nového mobilu. Kdykoliv změníte v nabídce značku nebo třeba rozlišení fotoaparátu či konkrétní model, URL adresa by se měla změnit. Ideálním tvarem je URL bez zbytečných parametrů (#,& apod.)
Kdy naopak nemít vlastní URL?
- V případě, že máte na webu použité rozbalovací menu, které se projeví po najetí myší.
- Při zobrazování skrytého obsahu, který není důležitý a chcete, aby se uživateli zobrazil až na jeho vlastní vyžádání.
2. Odkazy na stránce jsou jasně viditelné
Vyhledávače zkrátka potřebují poznat, že se jedná o odkaz. Nejlepším možným řešením je staré dobré HTML v podobě <a href=”url-adresa”>. Google dokáže přečíst i <map><area href=”url-adresa”>, ale lepší je klasické <a href=”url-adresa”>. Při kliku na odkaz stopněte akci a obslužte ji JavaScriptem. V neposlední řadě je dobré zmínit, že je třeba odkazovat na kanonickou URL.
Co vám vyhledávače neprojdou?
- <#>
- onClick (navigate nebo v kombinaci se span)
- <svg><polygon>
- Formuláře
3. Stop nekonečnému stránkování
Nekonečné stránkování, tedy infinite nebo endless scrolling, může na webu nasekat pořádnou paseku. Jedná se o lazy loading obsahu, který se načítá až vaším scrollováním. Může to mít výhody, ve své podstatě to má ale daleko víc nevýhod.
- Uživatel ve snaze najít, co hledá, proletí velkou část obsahu bez povšimnutí.
- Často nemáte šanci dostat se do patičky webu, kde jsou umístěné důležité informace (kontakt, formuláře ke stažení, otevírací hodiny apod.)
- Může se stát, že se prokliknete jinam a budete se chtít vrátit zpátky na původní stránku, která se ale načítá infinite scrollingem. Na poslední místo ve vašem scrollování se už nevrátíte.
- Pokud bude načítání pomalé, uživatel to může vzdát a odejde. Postupným načítáním se totiž může vytvořit pořádně dlouhá stránka.
Ideálním řešením je mít nekonečné stránkování dobře ošetřené. Na konec výpisu přidejte schovaný odkaz na předchozí a další stránku, aby to infinite scrolling vyhledávač prošel. Může to vypadat nějak takto <a href=“/3“>Další</a>. Nezapomeňte po načtení nové stránky opět změnit URL /3, jelikož jste měnili stav.
4. Posílejte správné HTTP kódy
SPA (single page application) mívá logiku stavů aplikace, ale i chyb na straně klienta. Vy je potřebujete dostat ze strany klienta na sever a předložit je vyhledávačům.
5. Neblokujte zbytečně robotům přístup k JS, CSS a API
Typicky se jedná o zákazy v robots.txt, které bývají špatně ošetřené. Za vidinou snadnějšího a rychlejšího zpracování se tvoří zákazy procházení, které ale mohou způsobit robotům problémy. Musíte robotovi dovolit, aby si sám mohl vyrenderovat URL adresy, které chce procházet a indexovat.
User agent: *
Dissallow: /css
Dissallow: /js
Příklad, jak by neměl zákaz procházení vypadat.
6. Přesměrovávejte správně
K trvalému přesměrování používejte stavový kód 301. Kód 301 musí být odeslán ze serveru dostatečně dlouho předtím, než prohlížeč provede JavaScript. Dejte si pozor také na zacyklené přesměrování. Každým dalším a dalším přesměrováním se natahuje čas načítání.
7. Testujte, testujte, testujte
Rada na závěr zní – testujte vše, co můžete.
- Typové stránky (kategorie, produkt, blogový příspěvek)
- Používejte nástroj URL inspector v Google Search Console
- V mobile friendly testu od Google Search Console (problémy s načtením stránky)
Kdy byste měli JavaScriptu z hlediska SEO věnovat pozornost?
Možná si ani nedokážete představit, jak moc JavaScript využíváte. Zkuste ho pomocí doplňku prohlížeče s názvem Web developer vypnout. Možná vás překvapí, kolik věcí nebude fungovat a kolik prvků se vůbec nezobrazí.
Co je problém?
Některé nedostatky jsou větší průšvih než jiné. Mezi největší problémy patří následující situace:
- Stránka vůbec nefunguje (bílá stránka).
- Stránka neobsahuje určitou část obsahu, který chcete mít v indexu.
- Neobsahuje odkazy vedoucí na podstránky, které chcete mít v indexu.
Co naopak není takový problém?
- Atraktivnější design a vizuální stránka webu. Samozřejmě za předpokladu, že to nebude na úkor obsahu.
- Generování fotografií a obrázků, které nechcete v indexu.
- Uživatelské funkce – kalkulačky, převodníky apod. Robot stejně neumí klikat, takže vykreslování tohoto prvku pomocí javascriptu ničemu nevadí.
Podívejme se na příklad, kdy je naprosto v pořádku, že po vypnutí JavaScriptu něco nefunguje. Na portálu www.hypotecnikalkulacka.cz si můžete spočítat nejvýhodnější hypotéku. Do kalkulačky zadáváte různé parametry – výše splátky, cenu nemovitosti, dobu splácení.
Bez JavaScriptu je kalkulačka nefunkční, odkazy pod ní ale fungují. A to je důležité.

Jak jsou na tom ostatní vyhledávače?
Ačkoliv je Google právem považovaný za nejpoužívanější vyhledávač, není na scéně sám. Dalším běžně využívaným vyhledávačem je např. Seznam.cz, Bing či Baidu.
JavaScript a Seznam.cz
Seznam.cz na stránku vůbec nemusí přijít nebo může odejít a prostě ji nezaindexovat. Samozřejmě i on na sobě stejně jako Google pracuje a už několik let se snaží indexaci javascriptových webů posouvat kupředu.
Umí Seznam.cz indexovat JavaScript?
Ano, částečně umí. Zvládne SSR i Dynamic rendering, respektive nebere Dynamic Rendering jako potenciální cloaking. Vylučovací metodou jsme tedy přišli o možnost nechat to na vyhledávači. Seznam.cz používá metodu hashbang. Jak sám píše ve své nápovědě:
Veškerý obsah stránek vytvořený pomocí technologie AJAX se načítá dynamicky na straně klienta a je pro robota (crawlera) neviditelný. S použitím techniky hashbang lze stránky napsané v AJAX indexovat.
Máme info od Jaroslava Hlavinky, že si Seznambot už nějakou dobu hraje s renderováním na straně klienta (client side rendering). Novinky z oblasti vývoje Seznamu doporučujeme sledovat na Twitteru.
Nenechávejte vše na vyhledávačích
Kdybyste si na závěr postavili do jedné řady 3 způsoby poskytování JavaScriptu, na plné čáře by vyhrál server side rendering. Hned v závěsu by byl dynamic rendering. Poskytnou vám větší jistotu, že vyhledávač JavaScript přelouská a zaindexuje.
S postupným rozvíjením rankbrainu a vylepšováním algoritmů vyhledávačů je technická stránka webu to jediné, co dokážeme s jistotou ovlivnit. Ačkoliv se budete SEO věnovat roky, vyhledávače stejně vždy přijdou s novinkou, kterou se dozvíte s určitým časovým zpožděním.
V závěru bych ráda poděkovala Jardovi Hlavinkovi, který je v problematice javascriptových webů jak ryba ve vodě. Veškeré moje znalosti se totiž opírají právě o know-how, které jsem si odnesla z jeho obsáhlého školení.
