
Filipa není v markeťácké komunitě nutné dlouze představovat. Patří mezi známé linkbuildery a SEO specialisty, jestli ne dokonce mezi ty nejznámější. Máme radost, že si na nás udělal čas a mohl vzniknout opravdu detailní rozhovor o Marketing Mineru, fungování Googlu nebo třeba mezerách, které na české SEO scéně vnímá.
Filipe, vnímám, že jsi taková ikona české marketingové scény. Začínal jsi jako linkbuilder a jako jeden z prvních veřejně řešil technické SEO v podobě témat analýzy logů a dalších. Tak trochu udáváš směr SEO tématům pro český trh. Co z toho vlastně nejvíc zajímá tebe v roce 2020?
Nevím teda, jestli jsem nějaká ikona, ale děkuju. Původně jsem začínal jako linkbuilder, to už je nějakých 14 let. Fuj, už jsem starej. Ale prapůvodně jsem působil jako SEO specialista v jedné menší firmě, kde jsem zjistil, že víc než SEO jako takové mě zajímal právě linkbuilding. Bavilo mě komunikovat s lidmi a řešit, jakým způsobem kooperovat s jinými weby.
Postupem času jsem se dostal k vývoji, částečně k produktu a mnohem víc mě začala zajímat technická stránka SEO. Fascinuje mě, jak se chovají vyhledávače na pozadí a to mě dost pohltilo. Díky tomu jsem se začal víc věnovat technické stránce SEO, Pythonu, machine learning a v tom pokračuji doteď. Je to tedy primárně technické SEO, o kterém teď nejvíce tweetuji, mluvím, se kterým jsem nejvíc v kontaktu.
Každopádně k tvojí otázce, co mě zajímá nejvíce v tomto roce, tak je to technické SEO, machine learning a v poslední době jsem si taky dost přičichl k managementu, jelikož Marketing Miner se rozrostl do určité úrovně a už je potřeba jej řešit.
A kdybys měl vytáhnout z technického SEA jednu oblast, kterou aktuálně řešíš nejvíc, co by to bylo? Kde vidíš potenciál něco zkoušet nebo přidat? Přece jen technické SEO je docela rozsáhlé.
Aktuálně mě nejvíc baví věci okolo Nature Language Processing/Natural Language Understanding. To znamená vše ohledně zpracování a porozumění jazyka a částečně i hledání toho, jak se vyhledávač chová, když zodpovídá dotaz uživateli.
Jak funguje na pozadí, když uživatel zadá dotaz? Jak rozeznat záměr uživatele při hledání (User Intent) a co tím vlastně myslí. Zaslouží si takový dotaz diverzitu kvůli více záměrům při hledání (Query Deserves Diversity)? Nebo čerstvý obsah (Query Deserves Freshness)?
Snažím se tak trochu dostat do hlavy vyhledávače a zjistit, co je pro něj nejlepší odpověď na určitý dotaz, protože mi to hodně dává i v mé práci.
Pokud bych ale z technického SEO obecně měl vytáhnout 3 věci, ve kterých vidím v českých projektech často mezery, tak je to:
- Analýza logů
- Analýza interního prolinkování
- A/B testování
Tyto tři oblasti se týkají kontinuálního progresu na projektech. Hodně se zaměřujeme na jednorázové nebo krátkodobé aktivity jako je klíčovka. Moc se ale nesoustředíme na to, jak s klientem pracovat potom.
S tím určitě souhlasím. SEO je u mnoha lidí spíš pocitové a zapomínají vyhodnocovat, jestli to opravdu funguje. A/B testování je za mě možná jedna z nejdůležitějších věcí.
My jsme se aktuálně dostali do doby, ve které nemůžeme říct, že existují nějaké obecné faktory pro řazení výsledků vyhledávání, spíše něco jako query based ranking factors (faktory na základě hledaného dotazu). To znamená, že nemůžeš říct, že pokud tohle funguje na jednom trhu, tak na druhém bude fungovat to samé. A zároveň nelze tvrdit, že pokud u jednoho dotazu platilo tohle, u druhého to bude taky tak. Vyhledávače začínají poměrně dobře chápat, jaký obsah uživatelé očekávají a podle toho jim přizpůsobují odpovědi.
Takže nezbývá než testovat. Už nejsme v době, kdy bychom mohli říct, že delší text je lepší nebo že když do titulku přidáš emoji, tak se zvedne CTR a pozice.
Díval jsem se na tvůj web a máš tam nabídku různých auditů. Kolik procent tvého času ještě zahrnuje práce pro klienty? Může si tě člověk najmout nebo máš beznadějně plno?
Na web už hrozně dlouho nepíšu. Mám koupenou i doménu podstavec.com a rád bych web časem předělal a psal tam už ne třeba tolik kolem linkbuildingu, ale více o technickém SEO a tématech okolo toho. Jak se nám vede, co mě kde zaujalo a co se dá udělat v rámci propagace nějakých Saas.
Co se týče spolupráce, drtivou část věnuji Marketing Mineru, kde mám nemalou část času vyčleněnou na sebevzdělávání. Myslím, že je to jedna z hlavních věcí, kterou musíš dělat, pokud chceš produktově nějaký nástroj vést. A zároveň mám vyhrazenou malou část času na klienty, abych měl kontakt s tím, co se děje a nevypadl z práce, kterou specialisté běžně dělají.
Většinou si k tomu nabírám nějaké zajímavosti typu „Něco nám tu spadlo a potřebujeme s tím něco udělat“. Nebo klienty, kteří mají nápad, potřebují pomoct s exekutivou a jsou do toho nadšení (dá se očekávat, že se bude opravdu zapracovávat a bude co měřit) nebo to datově podložit. Už nedělám klasickou práci SEO specialisty. Je to spíše o takovém mentoringu.
Kdybys to měl odhadnout, kolik času zhruba strávíš vzděláním?
Cca 30 % času je sebevzdělávání. 60 až 65 % dělá to, že něco nového navrhuju nebo dělám na Mineru a 5 až 10 % věnuju zakázkám bokem.
Významným tématem, se kterým jsi přišel, bylo Open Refine. Všichni si pamatujeme tvoji přednášku na Marketing Festivalu, kde jsi představil volně dostupné skripty a na ně navázaly tvoje PodstavecTools. Byla to taková předzvěst nějakého pokročilejšího nástroje?
Rozhodně. Byla to doba, kdy jsem začal do vývoje trochu víc sahat. Nejsem vývojář. Kdybych napsal něco v Pythonu a viděl to profík, tak by to možná nerozdýchal. Ale už jsem něco uměl. A moje přednáška předznamenávala to, že jsem se chtěl pustit do automatizace věcí, které běžně SEO specialista dělá.
To téma mě fascinovalo a provádělo i u Open Refine workshopu. Poměrně hodně věcí, co jsme měli na workshopu, bylo vlastně udělaných tak, že jsem k tomu připravil nějaké jednoduché REST API, ze kterého si účastníci stahovali data. Součástí toho bylo, že jsem vyvíjel i PodstavecTools (původní název MM), které byly vázané právě na Open Refine.
Pak začali SEO specialisté používat PodstavecTools ve větším a mně začal padat server, na kterém byl třeba i web truhlářství mého táty. Musel jsem to nějak zastropovat. Udělat registraci, API klíč a tak se postupně rodil Marketing Miner.
Už tehdy jsi plánoval, že se to takto rozvine?
Ne. Prapůvodní záměr nebyl vůbec dělat něco placeného. Byly to ze začátku funkce, které hodně pomáhaly mně osobně a pak jsem je jednoduše poskytoval ostatním. V okamžiku, kdy už se daly nakupovat kredity na těžení, to už bylo jiné. Od té chvíle jsem si přál, aby Marketing Miner co nejvíc vyrostl a vydal jsem se směrem budování Saas.
Na začátku jsme měli cca 15 platících, teď jich máme přes 400. Denně zpracováváme okolo 0,5 milionu řádků na vstupu a v řádu stovek jednorázových reportů. Momentálně přidáváme dotazy s hledaností alespoň 5 za měsíc a zaokrouhlujeme je na 10. Nová databáze má kolem 25 000 000 hledaných dotazů jen pro Česko. Aktuální měla asi jen 5 000 000. Myslím, že kdyby mi před 5 lety někdo řekl, kam se nástroj dostane, byl bych pěkně překvapený.
Pro ty, kdo Marketing Miner neznají, mohl bys ho blíž představit?
Obecně říkáme, že je to data mining nástroj pro online marketingové specialisty. Máš v něm všechna data pod jednou střechou. Ta nejjednodušší představa je, že přijde SEO nebo i PPC specialista a potřebuje obohatit nějaká data. Má třeba 100 000 klíčových slov a potřebuje k nim přidat další návrhy nebo hledanost. Nebo má sitemapu, kde je třeba 1 000 URL adres a on potřebuje získat informaci o tom, jestli je URL zaindexované, nebo ne.
Marketing Miner je prostředník. Nahraješ data, necháš si je zpracovat a my je obohatíme o to, co si zvolíš. To je asi ta nejdůležitější funkce. Kromě jednorázových hromadných reportů tam jsou ještě Profilery a Projekty.
Profilery fungují tak, že vložíš klíčové slovo nebo doménu a my ti vrátíme všechno, co o něm/ní víme. Získáš tak návrhy klíčových slov a témat, u domény zjistíš, na která klíčová slova inzeruje, jaké používá technologie a další. Jsou to data, která poskytují určitý nadhled nad trhem a dokážou dát dobrou představu o tom, jak jsi na tom v porovnání s konkurencí nebo případně jaký obsah by bylo dobré začít tvořit.
Poslední sekce, která poměrně roste na oblibě, jsou Projekty. Slouží ke kontinuálnímu měření webu. Máš nějakého klienta, založíš mu projekt a tím začneme průběžně monitorovat, na jakých pozicích se vyskytuje ve vyhledávačích, případně s jakými rozšířeními. Dostaneš i další agregovaná data – jestli roste/padá, srovnání s konkurencí, kde se o jeho brandu kdo zmínil a tak dále.
Aktuálně pracujeme na sekci Alertingu. Zaškrtneš, co všechno chceš monitorovat, a my to každý den sledujeme. Když se něco stane, dáme ti vědět. Například si každý den stáhneme tvůj robots.txt a jakmile dojde ke změně, dostaneš upozornění. Momentálně to funguje tak, že si nacrawlujeme web, určíme pár typových stránek, které se liší, a ty denně kontrolujeme. Teď si bude moct uživatel nastavit, jaké URL chce kontrolovat, ale zároveň mezi to přibudou základní kontroly jako jestli se například nezměnil titulek.
Kdybys to měl nějak shrnout, pro koho je nástroj určený?
Už od samého začátku byl Marketing Miner pro odborníky. Nemohl ho používat ten, kdo neuměl s API. V poslední době se snažíme víc pracovat na UX, děláme A/B testování, máme navržené změny v mnoha sekcích. Náš cíl je, aby byl i méně zkušený uživatel schopný pracovat v pracovat s MM. Vše bude v budoucnu intuitivnější a jednodušší.
Bokem teď děláme ještě jednu věc, kterou interně nazýváme AkadeMMie. Je to set návodů. Může to vypadat tak, že řekneme: „Přejdi sem, propoj se se svou search konzolí. Naimportuj dotazy, z nich si vytáhni hledanost a vyfiltruj ty, které mají hledanost nad 100. K nim si zjisti pozici a nějakou klasifikaci a z toho si poznamenej tyhle typy webů.“
AkadeMMie budou návody, které půjdou od 0 až po předání klientovi a zapracování do projektu. Myslím, že to bude poměrně velký krok kupředu a díky tomu se posuneme i víc k veřejnosti.
Marketing Miner má neskutečné množství funkcí. Víš, co v něm uživatelé používají nejčastěji?
Určitě jednorázové reporty, na kterých jsme to celé odstartovali. Pokud bych počítal unikátní počet použití, tak by vedly Profilery. Ale to proto, že stačí vložit jediný dotaz a máte data. I Projekty jako takové začínají dost růst. Od doby, co jsme je předělali, jsme zaznamenali dost přechodů od jiných nástrojů právě k Mineru. Dodělávali jsme teď například převodník dat z jiných nástrojů (hodně uživatelů chtělo přejít se zachováním historických dat o pozicích) a další věci, o které uživatelé žádali.
Ale myslím, že až doděláme návody do AkadeMMie, tak opětovně zažijí boom Reporty. Když se podíváš do světa, tak jiný podobný nástroj s přístupem, kde na vstup vkládáš hromadná data, která „obohacuješ“ z různých zdrojů do jednoho výstupu, tak není. Výjimkou je ČR, kde naši konkurenti již tuto funkci dodělávají.
Na jakých trzích MM působí? A liší se nějak nabízené funkce napříč trhy?
Marketing Miner aktuálně působí primárně na českém a slovenském trhu. Máme pro ně největší databáze. Aktuálně podporujeme i Polsko. Máme pro něj databázi a čekáme na překlady. Je to první stát, do kterého bychom rádi během následujícího půl roku expandovali. Chceme začít postupně. Zjistit reakce a pak třeba postupně rozjíždět další trhy.
Proč právě Polsko?
Dělali jsme výzkum ohledně kvality nástrojů, rozpoložení státu vůči nic a podobně. Třeba v Německu je SISTRIX. Konkurovat bychom mu možná mohli v případě, že bychom měli desítky milionů a dost času. I tak si ale myslím, že jako česká firma bychom pro ně nebyli zajímaví.
V Polsku funguje hlavně Senuto a SEMrush. Pro SEMrush Polsko nějak zajímavé je, ale není to nic extra. A Senuto je sice lokální, ale má dost mezer. Můžeme ho tedy v něčem přetlačit. Navíc Polsko je kousek, takže tam mohu dojíždět i na nějaké akce a mít osobní kontakt s potenciálními klienty.
Původně jsme chtěli do Nizozemska a Velké Británie. U VB jsme narazili na problém s nemalou vstupní investicí, která by byla určitě potřeba. Hledaných klíčových slov by tam bylo třeba 20x víc než tady, a to už je úplně jiná náročnost.
Jak se vůbec technicky plánuje rozvoj takového nástroje?
Je potřeba mít dobrého technického člověka, který vývoj zaštítí technologicky a nějakou představu, jak má nástroj vypadat za X let, respektive kam to chceme dotáhnout. Proto jsem hrozně rád, že na toto máme výborného vývojáře Honzu Smitku, který aktuálně vede vývojový tým Marketing Miner.
Občas vnímám, že vyhledávače, zejména Google, se takovým nástrojům usilovně brání. Je těžké s takovým kolosem bojovat?
Google nechce poskytovat žádná oficiální API k výsledkům vyhledávání. A tlak od těch nástrojů na to je, osobně bych raději ta data kupoval i za vyšší cenu přímo od Googlu, než dále scrapoval. Google poskytuje jenom Custom Search Engine, který vrací hodně rozdílné výsledky vyhledávání a nedá se použít.
S tím se pojí poměrně zajímavé téma. Google ve svém Keyword Planneru poskytuje hledanosti ve formě clusterů. Vysvětlil bys, o co jde a zda má MM nějaké vhodnější řešení?
Google Ads aktuálně slučuje hledanosti podobných dotazů. To znamená, že pro různé varianty podobného dotazu vám nevrátí informaci o jeho hledanosti, ale pouze kumulovaná data za všechny podobné dotazy. Například pokud máš dotazy „pračka, pračky, pracka, pracky“, vrátí ti jen slovo „pračka“, k němu hledanost a CPC pro všechny 4 varianty toho dotazu. Už ti neřekne, který dotaz je nejhledanější a jaké jsou statistiky jednotlivých dotazů.
Pro SEO specialistu je to poměrně problém. Pro vyhledávače je dotaz „pračka“ a „pračky“ obrovský rozdíl. Jednou jde o produkt, jednou jde o kategorii. Toto chování Google Ads je obecně známé, ale to, co už mnoho lidí neví, je, jak nekvalitní data v poslední době Google Ads poskytuje.
Google Ads začal v poslední době dělat třeba jednu zajímavou věc. I v clusterech se chová nejednotně. Dřív, když jsi tam dal „pračka, pracka, pračky, pracky“, tak to zclusteroval a pak ti vrátil slovo „pračka“, protože to třeba bylo hlavní slovo toho clusteru.
Když dám na vstup, že chci třeba „pocasi, počasi, počasí“, tak jako výstup dostanu „počasí“ s průměrným měsíčním vyhledávání 5 000 000. Když dám ale „pocasi, počasí“ (pouze obrátím pořadí), najednou je ta primární varianta „pocasi“. Takže když toto budeš dělat postupně do klíčovky, tak on ti vlastně bude vracet několikrát nejen stejnou hledanost a neurčí ani správný cluster.
A největší fuck up je, když dám třeba „Sazka, sázka“, ukáže mi, že Sazka má v clusteru sazka a sázka a má hledanost 165 000. Když to otočím a zadám „sázka, Sazka“, tak se to identifikuje jako stejný cluster, ale vrátí mi hledanost 720.
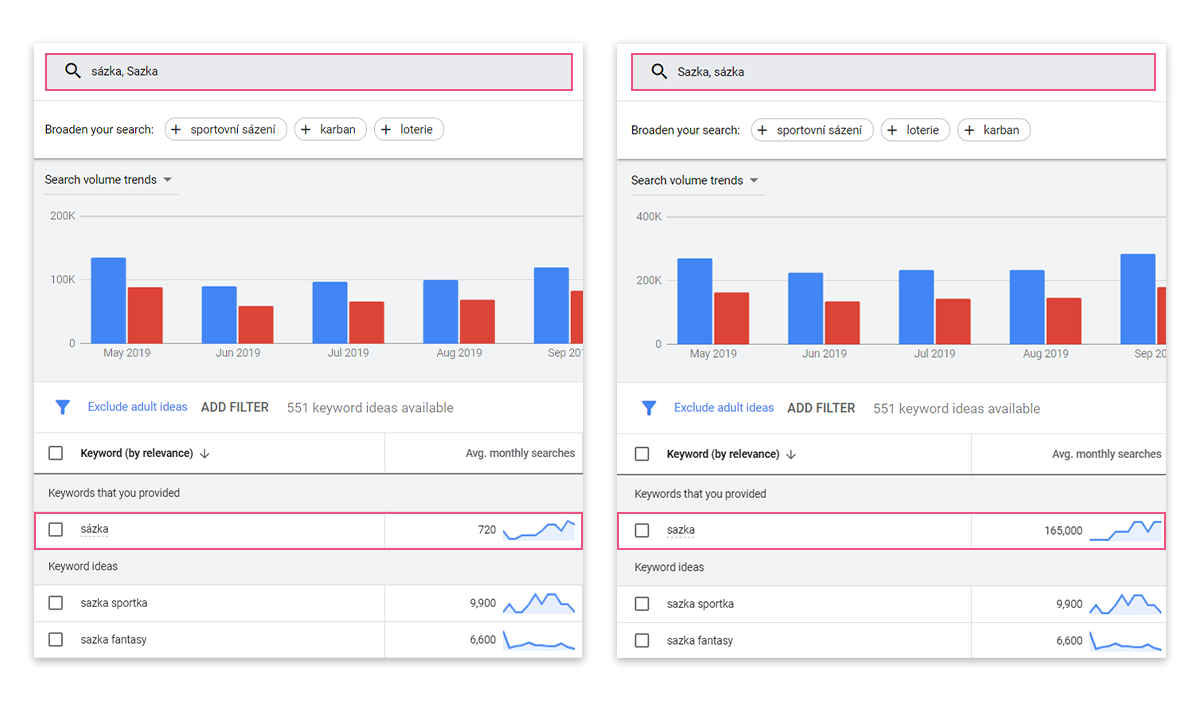
Jak to řeší Marketing Miner?
MM má data třetí strany. Díky tomu máme vzorek populace, podle kterého dokážeme odhadnout reálnou hledanost jednotlivých dotazů a k tomu si taháme i hledanost z Google Ads, data o impresích a Google Trends. Pomocí machine learning algoritmu pak určujeme, jaká je reálná hledanost. Jsme schopni říct, že slovo pračka je hledané 6 500x, slovo pračky 3 200x, pracka 2 000x a pracky 1 000x třeba. Takže jsme schopní uživateli odpovědět na dotaz, která z variant je hledaná, jestli produkt, nebo kategorie, a jaké varianty existují.
Do jak velké hledanosti půjde vaše nová databáze?
Nová databáze bude pro Česko mít přibližně 24 milionu hledaných dotazů na Google a půjde tak o asi největší aktualizaci naši hledanosti. Uživatelé to pocítí nejen na přesnosti výstupních dat, ale také na rozsahu dat poskytovaných v návrzích klíčových slov.
Například pro slovo „pračka“ nyní navrhneme 1 709 hledaných návrhů klíčových slov. S novou databází to bude kolem 20 000 návrhů.
Takových vlastních řešení má MM patrně víc. Namátkou z pohledu SEO určitě mohu vybrat výpočet konkurence v organickém vyhledávání. Jsou i nějaká další řešení, která bys chtěl zmínit?
Momentálně si víc hrajeme se zmíněným machine learningem. Máme tam 2 řešení, která začínáme implementovat do jednorázových minerů. Jeden z nich je identifikace sémantické vzdálenosti dotazů od kořenových klíčových slov.
Představ si to tak, že zadáš na vstup 10 000 klíčových slov a doplníš to informací o tom, že toto je 5 nebo 10 nejrelevantnějších dotazů. MM se podívá na těch 10 000 a zjistí jejich tematickou vzdálenost od těchto kořenových slov. Takže si můžeš jednoduše vyfiltrovat dotazy, které nejsou relevantní pro tvůj web, třeba do analýzy klíčových slov.
Druhý, který aktuálně ladíme, je automatizovaná klasifikace. Tam už jsme na úplně na jiné úrovni, než co jsme ukazovali na SEO restartu. Bude to ještě chvíli trvat, na druhou stranu výstupy z něj jsou super.
A co se týče nějakých unikátních řešení, to je přístup. Uživatel přijde, něco vloží a hromadně si to nechá obohatit o cenná data. Takový přístup jako prioritu žádný zahraniční nástroj nemá.
Podle čeho stanovujete, kterým funkcím se v dalším rozvoji bude věnovat? Má i běžný uživatel možnost někde navrhnout funkci, která mu chybí?
Feedback uživatelů je pro nás důležitý. Urovnává nám priority. Lidi nám píšou na supportu a máme i skrytou facebookovou skupinu Marketing Miner Internal. V ní jsou lidi, kteří chtějí testovat nové funkce, ale slouží i pro feedback. Zvažuji i založení další, spíše diskuzní, skupiny.
Máme dlouhodobou vizi na zhruba 2 – 4 roky dopředu, ke kterým systematicky směřujeme. Tento směr samozřejmě do určité míry modifikuje uživatelský feedback a návrhy. Bugy řešíme rovnou a menší změny, která by nezasáhnou do celkové strategie také zařazujeme. Na druhou stranu nechceme z každé strany nalepit to, o co si uživatelé řeknou, jinak by z toho vznikl časem paskvil. Snažíme se držet určitý koncept.
Jak si může nepolíbený uživatel nástroj vyzkoušet?
Máme testovací verzi tarifu zdarma. Uživatel jej může v omezeném módu používat na neomezenou dobu. Lidé nám občas píšou, že by si chtěli vyzkoušet plnou verzi, což se taky dá.
Na závěr bych se rád zeptal – Marketing Miner má rozsáhlou sekci nápovědy a pravidelně pořádá i webináře. Plánuješ v blízké době nějaký další pro nové uživatele, kteří by s ním chtěli začít?
Plánujeme větší webinář pro Marketing Miner. Ukážeme si průchod nástrojem, nebudu ukazovat jen základy, bude to hodně praktické. Dozvíte se, co s datama můžete a pravděpodobně i měli dělat. Budu rád, když se přidáte. :)
